
It doesn't matter, according to Larry Dossey, M.D. in Healing Words, whether you remember to do it at the appropriate time or do it early or later. He says the action of mentally projected thought or prayer is "non-local," i.e. not dependent on distance or time, citing some 30+ experiments on human and non-human targets (including yeast and even atoms), in which recorded results showed changes from average or random to beyond-average or patterned even when the designated thought group acted after the experiment was over.I was perplexed. On the one hand, if there really was good evidence of mind-over-matter (and operating backwards in time, no less) you'd think it would be the kind of thing that would make the news, and I might have heard about it. On the other hand, if there is no such evidence, why would seemingly sensible people like Larry Dossey, M.D. believe there was? I had a vague idea that there were some studies showing an effect of prayer and some showing no effect; I thought it would be interesting to research the field. I had just written an essay on experiment design, and this could serve as a good set of examples. Our starting point will be a January 2007 interview with Dossey. A sidebar in that interview highlights five studies that Dossey puts forth as his best case that prayer and other mental intentional acts can have an affect on the health of patients:
- Achterberg, J et al. "Evidence for Correlations between Distant Intentionality and Brain Function in Recipients: A Functional Magnetic Resonance Imaging Analysis." Journal of Alternative and Complementary Medicine. 2005; 11(6):965-971.
- Byrd, R. "Positive therapeutic effects of intercessory prayer" Southern Medical Journal. 1988; 81(7): 826-9.
- Harris, W et al. "A randomized, controlled trial of the effects of remote, intercessory prayer on outcomes in patients admitted to the coronary care unit." Archives of Internal Medicine. 1999;159(19):2273-2278.
- Tloczynski, J and Fritzsch, S. "Intercessory prayer in psychological well-being: using a multiple-baseline, across-subjects design." Psychological Reports. 2002;91(3 Pt 1): 731-41.
- Cha, KY, et al. "Does prayer influence the success of in vitro fertilization-embryo transfer? Report of a masked, randomized Trial." J. Reproductive Medicine. September 2001; 46(9): 781-787.
- Leibovici, L. "Effects of remote, retroactive intercessory prayer on outcomes in patients with bloodstream infections: a controlled trial." BMJ 2001;323: 1450-1.
- Benor, DJ. "Survey of Spiritual Healing Research" Complementary Healing Research. 1990; 4(3): 9-33.
- Klingbeil, B and Klingbeil, J. Unpublished manuscripts from the Spindrift Institute.
Study 1: Achterberg (Saybrook); Distant Intentionality
The first study is by Jeanne Achterberg of Saybrook Graduate School and colleagues. She had eleven faith healers choose one subject each, who were placed in an fMRI machine. Then the healers would alternately send and not send positive energy to the recipients, in twelve periods of two minute each. The experiment measured the recipients' brain activity and attempted to determine whether there were differences between the "send" and "no send" states. When asked if there are any possible flaws in the study, Dossey said "I can't find any." Let's see if we can. (The "warning signs" refer to my essay on experiment design.)- Warning Sign I1: the experiment is not reproducible from the report. You can't tell what is being measured or how those measurements are compared. The experiment has not been reproduced, by Achterberg or by others. (Here's one way to look at lack of reproducibility: if nobody has reproduced a study, then every rational person who knows about the study and has the possibility of reproducing it has made the bet that the expected value of reproducing it is less than whatever else they are doing instead. Now if you could convincingly demonstrate what Achterberg claims, you should have an excellent chance of a Nobel Prize, which is about $1 million, plus the fame. I estimate the cost of an fMRI experiment like this is $5,000. So a rational person with the means who chooses not to reproduce the experiment is saying that the chance of it working is less than about 1% (depending on details of their utility function).
- Sloppyness/typos: the results sections says "One of the two clusters was highly statistically significant (p=0.000127)". But if you look at Table 1, you see that the other cluster is also statistically significant (p=8.51E-09, or 0.00000000851). Why wasn't that mentioned? In personal communication, Dr. Achterberg said that it was a typo, that it should have been 8.51. She also says that the p value for cluster 1 in Table 1 is a typo; it says 0.00127 but it should be 0.000127, as it appears in the RESULTS section and abstract. But if they are typos in Table 1, then there are paired typos, because the next column gives the logarithms of these numbers, which are consistent with 8.51E-09 and 0.00127, not with the numbers that Dr. Achterberg mentions.
- Warning Sign D1: lack of randomized
controls. The best control would be to put a similar number of
patients in the fMRI with no sender involved. But that is
expensive, so the next best thing is what the authors have chosen:
a block design where there are blocks of time with one kind of
stimulant interspersed with the other kind, in this case send and
no-send. The problem is that the pattern of send/no-send
intervals was the same for all subjects. The lack of
randomization on a subject-by-subject basis is a fundamental error
that can be fatal to the validity of the experiment. For example,
suppose that patients were nervous, or somehow otherwise in a
different brain state in the first two minutes of the procedure.
(Or bored in the last two minutes.)
All of this difference would be recorded for the "no-send"
state, potentially
resulting in a significant difference,
even though the difference was actually due to the timing, not the
sending. This confound could have been avoided if only the experimenters had
randomized the block order.
To demonstrate the problem, I did a simulation where I generated 480 random numbers per subject, representing the 480 time slices in the experiment. I repeated this generation of random numbers 20 times. I compared the send and no-send intervals of random numbers using a T-test; none of the 20 trials found a significant difference at the p=5% level. I then repeated the simulation under the assumption that subjects would be anxious when first entering the fMRI machine, that this anxiety would last for between one and two minutes (chosen at random uniformly), and that during the anxious period the fMRI signal would be chosen from the top 20% of output levels as compared to the non-anxious period. I repeated this simulation 20 times, and 12 of the trials showed a significant difference between the send and no-send intervals at the p=5% level; 5 were significantly different at the p=0.1% level. So you choose: does this experiment show that (a) everything we've discovered in centuries of observations of physics is wrong; (b) there is random variation when you deal with only 11 subjects; (c) patients can get nervous when encased in a large, noisy machine; or (d) something else.
- Warning Sign D6: it looks like the authors are trying to apply a statistical model with one too many free parameters; a potentially fatal flaw. fMRI is a great technology, but it relies on measuring changes in blood flow that take a few seconds to register. This is called the hemodynamic delay. Since we don't know for sure how long this delay will be, we need to deal with it in some way. One standard way to deal with the problem would be to ignore the first few seconds when we switch from send to no-send or vice-versa. This is called a break period. Also, another standard approach is to jitter the stimulus by a second or so -- rather than start every stimulus exactly on a boundary between recording slices, have some start in the middle of a slice. Achterberg et al. apparently did not use breaks nor jitters. How did they model the hemodynamic delay? The paper is not clear, but one sentence bothers me: "A goodness of fit statistic (r squared) indicates the degree of fit between the hemodynamic model and the actual brain activity during the time course recorded." To me, this suggests that the length of the hemodynamic delay is a parameter that is fit by some model; their software computes the delay period that best fits the model. Here's the flaw: with a free parameter, you can impose order on a process where order does not exist. To test this, I ran a simulation where I generated random numbers chosen uniformly from the range -100 to +100. I generated 11 sequences of numbers, corresponding to the 11 subjects in the experiment, and 480 numbers per sequence to represent an fMRI reading once every 3 seconds of the 24-minute experimental protocol. I then divided each sequence into twelve equal parts, corresponding to the off-on parts of the experimental protocol. I then computed the difference between the sum of the numbers in the on parts and the sum of the numbers in the off parts. But I did this allowing hemodynamic delays of from 0 to 30 seconds. By choosing one delay or another, I got the difference between the means to vary between 0.09 and 3.30. A difference of 0.09 is not significant (p = 0.95) while a difference of 3.30 is significant (p = 0.03). So, even with a sequence of random numbers, I can get a significant difference (or not), just by choosing my hemodynamic delay. If the authors' search for the hemodynamic delay parameter was anything like my simulation, then it is possible that the results reflect an artifact of the parameter choice rather than any pattern in the data. Unfortunately, one can't tell from the article exactly what they did.
-
Warning Sign D7: overzealous data mining. It
appears they were looking for changes in any part of the
brain. There are a lot of parts of the brain; if you look at
enough parts, you'd expect some to differ just by chance. They
should either decide ahead of time what areas are likely receptors
of the transmitted thoughts and look only at those, or do another
study looking only at the areas found to be relevant in a pilot
study. In personal communication, Dr. Achterberg writes: We
were "data mining," and doing absolutely the appropriate study for
a pilot endeavor. It seems we are in complete agreement: what
she did was perfectly appropriate as a pilot. Where we disagree
is what to do next. I would say that the next step after the
pilot study is to do a real study; the wrong thing to do is
publish the pilot as if it were real. Vaughan Bell writes about
the common
problem of data mining whole-brain imaging studies, rather than
zeroing in on the appropriate part of the brain with a separate study.
Craig Bennett and colleagues took a humorous look at this with a study involving the fMRI of a dead fish. They found the dead fish's brain showed statistically significant results in the experimental task. Their conclusion however is not that the dead fish can accomplish the task; rather it is that "relying on standard statistical thresholds (p < 0.001) and low minimum cluster sizes (k > 8) is an ineffective control for multiple comparisons". See the discussion on this at the Neuroskeptic blog.
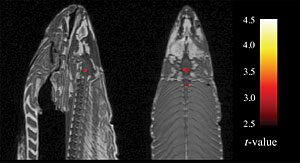 \
\
fMRI of dead fish brain - Warning Sign D8: lack of a theory. Since the experiment proposes an effect that contradicts known physics and physiology, there should be some explanation of how the effect is achieved. The authors say that "the results of this study may be interpreted as consistent with the idea of entanglement in quantum mechanics theory." This is a partial theory, but it raises more questions than it answers: how do the particles of sender and subject get entangled? How does that entanglement lead to a causal effect in the subject? How does a causal effect in a particle of the subject lead to a macro-effect on brain state? When we assess whether there is anything to this study, we need to assess whether there are answers to these questions.
-
The final flaw: the results are either poorly worded, or do not directly address the question of how the
period of time involving "sending" compares to "no sending".
Here is the entire RESULTS section, verbatim (my emphasis
added):
The FSL software produces a quantitative table of cluster results that includes: cluster size, probability for each cluster, z scores, x, y, z coordinates of the cluster in Talaraich space and contrast of parameter estimates (see Table 1). If a cluster is significant in a group analysis it means that there were specific brain regions in which the combined subjects had enough activation to raise the z score above the noise level threshold. In other words, if all of the subjects had random activation at different places in the brain, then there would be no group activation. One of the two clusters was highly statistically significant (p=0.000127). Significant areas of apparent activation in the group analysis and total number of pixels activated for the group are reported in Table 2. A scan representing the group activation as a whole appears in Figure 2.
It seems like what was done was: add up and average all the activations in the "send" condition, and subtract the activations from the "no send" condition. Then you get a single set of summed activations, and look for deviations from zero. Clearly, there were deviations, but that does not really address the questions. We want to know how the "send" and "no send" conditions compare; by lumping them all together, we've lost the ability to do that. Consider Fig. 2 from the article. We see a picture of total activation regions in two areas of the brain, but what we really want to see is a comparison: what does a brain (or an average over several brains) look like in the send condition, and how is that different from the no-send condition? The result section is saying that the subjects had activation at "specific brain regions" and "different places in the brain", but says nothing about how those activations are correlated with the time intervals of the conditions. Table 1, Table 2, and Figure 2 all mention spatial regions, but nothing about time intervals. In the DISCUSSION section, they do say "the results show significant activation of brain regions coincident with DI [distant intentionality] intervals." But they don't say whether there was also significant activation coincident with non-DI intervals. They correctly point out that "if all of the subjects had random activation at different places in the brain, then there would be no group activation." So they have proved that the activation in the brain is not random. But they have not proved that it is non-random because of the send vs. no-send conditions. It would have been easy to do a simple T-test or other test comparing the send vs. no-send condition, but they elected not to do that. So not only have they failed to prove their premise; they haven't even attempted to address it in the results sections. In the abstract they do say "Significant differences between experimental (send) and control (no send) procedures were found." Unfortunately, the results section does not back up that claim. Thus we can't evaluate the paper because we don't know what it is claiming.
{kind=link}
Study 2: Byrd (UCSF); Prayer for Cardiac Patients
Dossey says "The most famous prayer study was conducted by Dr. Randolph Byrd." (Actually, I (and many others) think Benson's study is most famous. But Byrd's is certainly well known.) Byrd's study is Positive therapeutic effects of intercessory prayer in a coronary care unit population, and was published in the Southern Medical Journal in 1988. Byrd studied 393 patients in a coronary care unit, split them into a control groups, and an experimental group for which a team of intercessors were given the subjects names and told to pray for "a rapid recovery and prevention of complications and death." Byrd then measured the death rates and three variables related to "rapid recovery" (length of hospital stay, length of coronary care unit stay, and re-admissions). There were no statistical differences between the two groups for "rapid recovery" or for "death".As for "prevention of complications," the story is more complicated. Byrd measured 24 other variables (see table 2 in the article); of these, 18 variables (such as requiring major surgery, angina, and gastrointestinal bleeding) showed no significant difference at the p=5% level, and 6 variables (such as heart failure, pneumonia and requiring antibiotics) did. But Byrd didn't declare before the study that these were the important variables. So it is a clear Warning Sign D7, overzealous data mining, to pick the 6 out of 30 significant variables after the fact. Certainly you can use these 6 variables to inform another study, but you can't count the results from this study. Furthermore, it is Warning Sign D6 to treat variables as independent when they are not. For example, congestive heart failure automatically leads to a need for diuretics; Byrd counts these as two separate significant results. That's like saying you had a positive result on both "temperature (Fahrenheit)" and "temperature (Centigrade)."
Byrd goes on to get a positive result with p=0.1%, but he does this by inventing a scoring method for adding up the various measures. This is Warning Sign D7 again: Byrd made up the scoring method after the data was in; he should have made it part of the hypothesis before the data was gathered. This is also a Warning Sign D2, lack of a double-blind study. Although the patients and Byrd were blinded, Byrd was not blinded when he made up this scoring method, and his assistant, Janet Greene, was not blinded throughout, even though she interacted with the patients and did data entry. There is also a problem with Warning Sign D3, too few subjects. Although 393 subjects sounds like a lot, far fewer had serious problems. For example, 7 patients in the control group had cardiopulmonary arrest, compared to 2 in the prayer group. The difference is significant, but the numbers are very small.
This study appears to be done fairly well, with good randomization and controls, although some problems with blinding. The results are inconclusive: some variables are positive; some negative. Byrd has stated that the paper was rejected from two jourtnals before it was accepted to the Southern Medical Journal. The study should best be interpreted as a pilot study to help focus future research.
Study 3: Harris (University of Missouri); Prayer for Cardiac Patients
Given an inconclusive study like Byrd, a good idea is to try to reproduce it. Fortunately, an attempt was made by Harris et al. They replicated all the cases where Byrd found no significant difference, such as length of hospital stay and mortality. For the variables that Byrd found a significant difference, Harris found no significant difference. In fact, of the 35 variables listed in Harris' Table 3, only one, "Swan-Ganz catheter" showed a significant difference at the p=5% level. By random chance, you'd expect 1.75 variables to show significance at the p=5% level. But, Harris also commits Warning Sign D7, over-zealous data mining, to come up with three different scoring method from the one Byrd used--one of the three showed a significant difference, at the p=4% level. Tessman and Tessman have a further analysis.
Here's another curiosity about the Harris study: Nicholas Humphrey points out that there were some patients who did so well that they recovered and checked out of the hospital before any prayers could be organized for them. It turns out that four times as many of the "to be prayed for" group recovered quickly, compared to the "not to be prayed for" group. This is significant at the p=0.1% level. What conclusion can you draw from this? (1) someone was trying to slip more of the healthier patients into the "to be prayed for" group; (2) God preferentially heals people who are about to be prayed for, thereby causing them not to be prayed for; or (3) if you collect enough numbers and do enough data mining, you can find multiple statistically significant results? I prefer (3), but you take your choice.
Although this study is cited in the sidebar of Dossey's interview as one of the best studies, Dossey himself says in his book Healing Words that "this study has missed the mark. . . . we would expect greater evidence than a few small percentage points of improvement. We would want to see statistically significant life-or-death effects, which simply did not occur." I think that's an accurate assessment of this study, as it stands on its own. It should also be noted that this study fails to replicate Byrd's findings, so we can add Warning Sign I1: lack of reproducibility to both Byrd and Harris. Taken individually, Byrd and Harris are both professionally-done studies with mixed results: they suggest prayer may have an effect on some variables but not on the seemingly most important ones such as death rates. Taken together, they show that we don't yet have any single variable for which intercessory prayer works reproducibly. For those who believe in intercessory prayer to a responsive omnipotent being, this is difficult to explain: God can't affect death rates nor speed of recovery; all he can do is make you 5% less likely to need antibiotics in one out of two studies? It reminds me of Woody Allen's line: "If it turns out there is a God ... the worst that you can say about him is that basically he's an underachiever."
Study 4: Tloczynski (Bloomsburg University); Prayer for Anxiety
In this study, non-specific non-directive prayer was performed for subjects, who were undergraduate students in a psychology course. The hypothesis was that the prayed-for students would show a significant decrease in scores for anxiety, depression, college maladjustment and Type A behavior, as measured by standard tests of those indicators.The conclusion was that the prayed-for students had a significant decrease in anxiety, but no significant difference in the other indicators.
The first thing that stands out about this paper is Warning Sign D3: too few subjects. There were only eight subjects in the study. You can argue whether 20 or 200 or 2,000 subjects is appropriate, but clearly 8 is too few. The second issue is Warning Sign D1: lack of a control group. Due to the small number of subjects, the experiment used a multiple baseline single-case study, which means that all subjects start in the control group, and then they move to the treatment group at different times. (The "single-case" part means that each single subject is a complete control/treatment case.) In this experiment, all 8 subjects start in the non-treatment group. After a week, 2 subjects move to the treatment group (they are prayed for). After 3 weeks 2 more move, and again 2 more after 5 weeks. The final 2 subjects stay in the non-treatment group for all 7 weeks of the experiment. A third issue is Warning Sign D2: lack of a double-blind study. The subjects were not aware of their treatment status, but the experimenter was--in fact the experimenter was the one who performed the prayer. As the article points out, this has the advantage that the experimenter knows that the prayers were performed consistently, but the disadvantage that it is not blind: the experimenter/professor might be inadvertently signaling something to the subjects in class. In the article, the experimenter judges that there is only a very small risk of the experimenter doing this.
Multiple-baseline studies are designed for cases where it would be unethical to withhold treatment. They are popular in education studies. You can't take half the class and say "we're not going to teach you to read." But you can teach different things to different parts of the class at different times of the year. According to Barger-Anderson et. al (2004), Warning Sign I1 (lacking reproducibility) is particularly important in single-case designs. They state, "Many replications of any single-case research design are needed to prove cause-and--effect relationships. Further, no experiment, regardless of the method, should create a general assumption of a cause-and-effect relationship after only one completion of the study." Indeed, the question of cause-and-effect is the key one for this experiment. Here is the data from the experiment, presented two ways:
On the left we see anxiety scores for each of the 8 subjects. Each subject has a different color, and the data points with circles are before prayer started for the subject; the points with crosses are after the subject was prayed for. On the right we see average scores for each week of the experiment. The orange line with circles is the average score of those who were not prayed for, the green line with crosses for those who were, and the grey for all subjects. The grey line shows a decline over the seven weeks of the experiment. Is that because something outside of the experiment tended to make the students less anxious? Or is it the fact that more subjects are being prayed for over time that makes them less anxious? Unfortunately, this study can't distinguish. Is it noteworthy that the cumulative anxiety of all the not-prayed-for students goes down, and the cumulative anxiety of the prayed-for goes up over time? The experiment doesn't answer these questions.
Consider the blue-line subject in the left-hand figure; this subject is abut 50% more anxious than the others. As we see in the right-hand figure, when anxious guy is in the nontreatment group (weeks 1-3), his group (orange circles) has above-average anxiety scores, and when anxious guy switches to the treatment group (weeks 4-7), that group has above-average anxiety. Could one subject explain all the results of the experiment? In the end 8 subjects are just too few to draw any conclusions, especially when the 8 are trying to do double duty as test and control.
Ladies and Gentlemen, you need a proper control group! If you think you have a clever experimental design that gets around the need for a control group, carefully write down all the reasons you think it works on a piece of paper. Study the paper carefully. Then throw away the paper and get a control group anyway.
Gary Loveman, an executive at the Harrah's (casino) company, echoes this sentiment, telling the Wall Street Journal "There are two ways to get fired from Harrah's: stealing from the company, or failing to include a proper control group in your business experiment."
That said, there are cases where you can't have a control group, for ethical reasons. For example, Smith and Pell (2003) jokingly doubt the efficacy of parachutes when jumping out of planes, because there are no studies with a control group that gets no parachute. But for most situations where death is not on the line, find a way to incorporate a control.
Also, I applaud the use of a quick eight-person experiment as a pilot study. In this case, the pilot study could have been used to suggest that an actual experiment look at anxiety and not the other three variables (which showed no effect at all). The mistake in this case, as in the Achterberg case, was to publish the pilot study; it would have been better to do a real study with a sufficient number of subjects.
Study 5: Cha (Cha Hospital, Korea); Prayer for Pregnancy
The next study, by Cha, Wirth, and Lobo in 2001, claimed that prayer doubled pregnancy rates for in vitro fertilization patients, at p = 0.1%. However, the validity of the study has been called into question:- The authors failed to obtain informed consent; neither the patients nor their doctors were told about the experiment. This by itself does not dispute the results of the study, but it is considered unethical, and launched an investigation by the home institution, Columbia University.
- In the wake of this controversy the lead author, Dr. Lobo, claimed that he had not even heard of the study until 6 to 12 months after it had been completed. Lobo withdrew his name from the paper.
- The second author, Daniel Wirth, a parapsychologist with no medical training, was the one who actually executed the experiment. He has been accused of completely fabricating another study. In May 2004 he pleaded guilty in a Pennsylvania court to thirty-five counts of mail fraud, bank fraud, and other felonies. He stole over $3 million using false identities. He was sentenced to five years in federal prison.
- The Journal of Reproductive Medicine withdrew the paper from its web site.
- In February 2007, the final author, Cha, was censured by the Journal Fertility and Sterility for plagiarizing, almost word for word, a paper published by Jeong-Hwan Kim in another journal, and perjuring himself by signing a statement that the work was original. Cha was banned from publishing in Fertility and Sterility for three years and has left Columbia.
So we're left with zero authors associated with the study who have not been penalized for fraud. Believing this study looks like a Warning Sign I8: believing liars and cheats.
Study 6: Leibovici (Rabin Medical Center, Israel); Retroactive Prayer
Now let's move on to the final study cited by Dossey as an "amazing example." This is a study by Dr. Leonard Leibovici of the Rabin Medical Center in Israel, appearing in the British Medical Journal in December 2001. In 2000, Leibovici looked at patients admitted to the hospital for brief stays in 1990-96. He randomly assigned them to one of two groups, and had prayers said for the members of one group. The control group got no treatment. Mortality rates showed no difference, but subjects in the prayed-for group had less fever and shorter hospital stays, significant at the p=4% level.Note that the praying was all done 4 to 10 years after the patients had either recovered or died. So this means--what? It is not clear. By our current understanding of time and causality, the results of the experiment were already determined as soon as the patients were assigned to one group or the other. There was no need to actually do or not do the prayer, since the results had already occurred, and could be computed right then and there. An alternative explanation, requiring a new understanding of time and causality, is that the prayer in 2000 somehow changed the patients outcomes in 1990; or maybe the prayer had just affected the assignment of patients to the control or prayer group. What is Leibovici's take on this? He says:
The purpose of the article was to ask the following question: Would you believe in a study that looks methodologically correct but tests something that is completely out of people's frame (or model) of the physical world--for example, retroactive intervention or badly distilled water for asthma?
Leibovici answers his own question as follows:
if the pre-trial probability is infinitesimally low, the results of the trial will not really change it, and the trial should not be performed. This, to my mind, turns the article into a non-study.
Here Leibovici is saying that his whole purpose in publishing the study was to point out what I called Warning Sign I4 (confusing P(H|E) with P(E|H)). His reasoning is as follows: what's the prior probability (before the experiment) that thoughts can influence events in the past? We have no evidence of it ever occurring, we have no theory for how it could occur, but we have copious evidence and theory that says that it does not happen. So reasonable values for the prior probability of it happening in this case could be anywhere from one in a trillion to one in a googolplex. If we believe the experiment, which comes in at a p=4% level, we should update the probability to a higher value, but the result is still infinitesimally small, so Leibovici's point is that the experiment doesn't matter.
Note that the article was published in the Christmas issue of the British Medical Journal, which traditionally includes articles of a light-hearted or humorous nature (such as the Smith and Pell December 2003 paper on the efficacy of parachutes). Clearly, Leibovici and the editors meant it as a kind of joke, to challenge our understanding of statistical results. (This subtlety was lost on many commenters.)
I think the most interesting comment was by Martin Bland of the University of York. He essentially has a logical proof that an ethical study proving the efficacy of retroactive prayer is logically impossible. The proof goes like this (my words):
According to Clause 30 of the Declaration of Helsinki, "at the conclusion of the study, every patient entered into the study should be assured of access to the best proven prophylactic, diagnostic and therapeutic methods identified by the study." Now suppose you have done a study proving retroactive prayer works. If you don't offer retroactive prayer to the control group, you're being unethical. If you do offer it, then the control groups should be retroactively cured. Thus, in the end there should be no difference between the control group and the treatment group, and therefore the study cannot show an effect.
One final issue is what I call Warning Sign D8 (lack of a theory). First Dossey argues that a theory is not necessary:
No mechanism known today can account for the effects of remote, retroactive intercessory prayer ... However, the significant results and the flawless design prove that an effect was achieved. To quote Harris et al: "when James Lind, by clinical trial, determined that lemons and limes cured scurvy aboard the HMS Salisbury in 1753, he not only did not know about ascorbic acid, he did not even understand the concept of a `nutrient.' There was a natural explanation for his findings that would be clarified centuries later, but his inability to articulate it did not invalidate his observations."
He has a very good point that this experiment by Lind -- one of the first applications of the scientific method to medicine -- was done without a modern theory of vitamins or nutrients. However, as I point out in D8, Lind had a perfectly good partial theory: "diet affects health". This partial theory constrained the design of Lind's experiment. For example, if he fed limes to seaman Smith he would then look for a change in Smith's health in the following days or weeks. He would not look for a change to Smith in the past, nor for a change in the seaman who carried the limes to Smith.
Dossey goes on to propose his own partial theory for retroactive causality: "In one of the most profound discoveries in science, a new class of phenomena was recognized: "non-local events," in which distant happenings are eerily linked without crossing space, without decay, and without delay." Here he is using the theory of Quantum Electrodynamics as a metaphor for something eerie, but he's not saying exactly what. Dossey is correct in pointing out that experiments on subatomic particles are consistent with the idea of nonlocality, and Einstein did indeed call this "spooky action at a distance." Does quantum theory license Dossey's idea that anything goes--mind over matter, prayer working backwards in time, whatever; it's all non-local? Dossey seems to think that there's plenty of slop in Quantum theory; it all seems so strange, so anything's possible; why couldn't thoughts affect a patient's health a decade before?
This invocation of nonlocality may work as a metaphor, but it doesn't work as physics. It is true that photons act nonlocally, but what connection does that have to consciousness? Or to macroscopic causation going backwards in time? I know of no evidence nor any theory that would account for this. Furthermore, Quantum Electrodynamics is actually the exact opposite of "anything goes." It is the most precise, most predictable theory ever invented in any field. For example, before Quantum theory the magnetic moment of the electron was defined as 1 Bohr magnetron. From the theory you can see that this is actually an approximation, and the more precise value can be calculated as 1.0011596525 Bohr magnetons; this matches the experimentally derived value of 1.0011596522 magnetons to 10 digits of accuracy. Compare that to the gravitational constant, 6.67428 × 10-11 N m2/kg2, which has only 6 digits of accuracy. According to physicists, Dossey would have a ten-thousand-times better argument if he invoked gravity rather than quantum theory as his metaphor. After all, gravity is nonlocal as well. Two objects with mass are "eerily linked without crossing space, ... and without delay" by gravity. But of course, gravity does not sound as mysterious as quantum forces, so it would sound silly to say "gravity is nonlocal and we don't understand it completely, therefore thoughts can influence events in the past."
But let's drop physics and get back to statistics. Dossey disagrees with Leibovici's take on his own experiment. Dossey says "Leibovici's auto-rejection brings a dangerous level of arbitrariness to the scientific process. Why disqualify one study and not another, when both had acceptable methods?" I totally agree with Dossey that there is no need to disqualify any study--a proper Bayesian analysis incorporates all the evidence. We should accept the results of any study for what they are worth--but no more. Similarly, we should accept any theory as a possibility--but give it an appropriate probability.
If, like Dossey, you have a prior probability of somewhere near 50% that thoughts can influence events in the past, then this study (if you believe it was reliably done) should, according to Bayes' Rule, cause you to update your probability to about 96%. If, like Leibovici, or most other people, you have a prior probability more like one in a trillion, then you should update to about 24 in a trillion.
Leibovici says this is close enough to no change that you can effectively discard the study. From a practical point of view he's right that you shouldn't spend much time worrying about possibilities that are 24 in a trillion. But from a theoretical point of view he's wrong--we should not discard the study completely, because if we accumulate 10 independent, unbiased confirmatory studies at the p=4% level (with no non-confirming studies), we should update all the way from 1 in a trillion to about 1 in a hundred, at which point we would want to treat the possibility very seriously indeed.
So what are the chances of quantum theory justifying causal effects in health backward in time? Is it one in two or one in a trillion? Nobel laureate physicist Steven Weinberg said "quantum mechanics has been overwhelmingly important to physics, but I cannot find any messages for human life in quantum mechanics that are different in any important way from those of Newtonian physics." There are mysteries in quantum theory, but not as to what actually happens--that can all be predicted out to the tenth decimal place. The only "eerie" part is why it happens that way. As Feynman put it: "While I am describing to you how Nature works, you won't understand why Nature works that way. But you see, nobody understands that. I can't explain why Nature behaves in this peculiar way."
Study 7: Benor (Wholistic Healing Publications); Spiritual Healing
Dossey also mentions a meta-study by Daniel J. Benor M.D. titled Survey of Spiritual Healing Research from the journal Complementary Healing Research. Benor looks at 131 studies and finds that 56 have positive results at a significance level of p=1%, while 75 do not. Does that constitute positive or negative evidence?If, like Gary Posner, you're a stickler for credentials, you'd say it constitutes no evidence at all, because these are all either unpublished student theses or from parapsychology journals, and not from established scientific journals. If you think that spiritual healing constitutes a new physical phenomenon (rather than just a medical treatment) then you, like Victor Stenger, would see a Warning Sign I6: accepting the wrong p value, and insist on the p=0.01% level of physics journals and would say that these are 131 out of 131 negative results. If you're a serious statistician, you would note that Benor uses a simplistic and error-prone technique called vote-counting. This is a clear Warning Sign D6: the wrong statistics. (See an analysis by Bangert-Downs and Rudner, which states "conclusions from vote-counting can be very misleading.") If you're Benor or Dossey, you say the jury is still out, but the fact that 56 is way more than 1% of 131 is evidence favoring spiritual healing (and you don't mention the 75 other studies).
Here's how I look at a meta-analysis like Benor's. A meta-analysis asks the question:
Assuming that (A) there is one single phenomenon that all these experiments are testing, and (B) there are no systematic flaws in the experiments, what is the probability that random variation in outcomes would lead to these results, given that the underlying phenomenon is positive (or negative)?
An arsenal of sophisticated statistical tools is employed to answer such questions, but we can bet a first-cut answer with a trivial analysis. First, suppose there is a real phenomenon. Then you would expect about 99% of studies (or 130 out of 131) to show it at the p=1% level, But we only saw 56 positive results; fewer than half the expected number. On the other hand, if there is no real phenomenon, we would expect only 1 out of 131 positive results, but we actually observed 56. Without even doing the math, it should be clear that the observed results are very unlikely either way. There is not enough data in the Benor paper to actually do the math, but I think the chances of the observed results given the assumptions are somewhere between 1 in a billion and one in 1030. Therefore, we should examine the assumptions.
We could question assumption (A) and posit some set of conditions under which spiritual healing works and some conditions under which it doesn't work, and see how the experiments match up with this theory. Or we could question assumption (B) and try to find flaws in some of the experiments that would explain the contradictory results. This seems promising since 6 out of 6 of Dossey's best examples of studies had numerous pervasive problems.
Here's one completely speculative possibility: assume that about 90% of these studies are flawed and should be discarded. Assume that leaves us with 6 positive and 8 negative studies at the 1% level. Assume that for every published study there are 42 unpublished negative results due to the file-drawer effect. This model fits eactly the expected number of positive and negative results if there were no effect of spiritual healing. Now I realize I made many assumptions in this speculative model. But even if you think there's only a one-in-a-million chance of this model being accurate, that's still thousands or billions of times more likely than the alternative suggested by Benor.
In the end, a meta-analysis only helps explain random error in sampling; it cannot explain systematic error in experiment design.
As an aside, I will mention the controversy over meta-analysis of mind-over-matter studies unrelated to healing. For example, the meta-study by Radin and Nelson (and a book by Radin) describes a total of 515 experiments by 91 authors on extra-sensory perception or ESP: a subject tries to guess the roll of a die or the next number from a random number generator. It turns out that the experiments report a persistent effect of slightly better than chance guessing, equivalent to guessing the flip of a coin a little less than 51% of the time, rather than 50%. This may not seem like much, but because the total number of trials is in the millions, it is very unlikely that this deviation happened by chance (something like a 10-50 chance). There was an exchange between Radin and the eminent statistician I. J. Good over the magnitude of the file-drawer effect necessary to explain the 51% disparity, but I won't go into that, because it really doesn't matter. It matters to Radin, because he thinks there are only two possibilities: either there is a file drawer effect, and the statistics show no anomaly, or there is no file-drawer effect, and therefore ESP is real. But for someone who can imagine other possibilities--perhaps the random numbers generated in the experiments were not completely random, and the subjects unconsciously picked that up, or perhaps there were errors in recording the results--this becomes a matter of "yes, I accept that there is a non-random effect here, but is it more likely that the effect is due to ESP or to errors in the experimental method?" Statistics can provide only a partial answer to that question. Skeptics point to a number of reasons for concluding that the results of the experiments are indeed non-random, but that the reason is not ESP: (1) the lack of an explanation for why the effect should always be at the 51% level, and not at 66% or 75%; (2) the detection of error or fraud in multiple past studies, (including all known cases of claims of high (e.g. 66% or 75%) results); (3) the lack of a physical theory; (4) the known fact that data recorders can easily make mistakes at the 1% level, and so on.
Study 8: Klingbeil (Spindrift Institute); Yeast and Atoms
What about those "30+ experiments on human and non-human targets (including yeast and even atoms), in which recorded results showed changes from average or random to beyond-average or patterned even when the designated thought group acted after the experiment was over"? As far as I can tell, these are all the works of Christian Scientists Bruce and John Klingbeil, who founded the Spindrift Institute in Oregon in 1969. They did experiments where they prayed for yeast, seeds, and other things. They had an excellent methodological idea -- eliminate the possibility of a placebo effect by using non-sentient subjects. Unfortunately their results were never peer-reviewed or published in scientific journals, making it difficult to evaluate them. The Klingbeils apparently did self-publish some of their experiments, shortly before they committed suicide in 1993, but I have been unable to find copies. It appears these studies have not been replicated by any other lab.Other Studies
- Benson H, et al. (2006). Study of the therapeutic effects of intercessory prayer (STEP) in cardiac bypass patents: A multicenter randomized trial of uncertainty and certainty of receiving intercessory prayer. American Heart Journal 151:934-942.
- Aviles JM et al. (2001). Intercessory prayer and cardiovascular disease progression in a coronary care unit population: a randomized controlled trial. Mayo Clinic Proceedings 76(12):1192-8.
- Sloan RP, Ramakrishnan R (2005) The MANTRA II Study The Lancet 366(9499):1769-70
- Masters S et al. (2006) Are there demonstrable effects of distant intercessory prayer? Annals of Behavioral Medicine Aug;32(1):21-6.
- Hodge D (2007) A Systematic Review of the Empirical Literature on Intercessory Prayer Research on Social Work Practice, Vol. 17, No. 2, 174-187
- Roberts L et al. (2009) Intercessory prayer for the alleviation of ill health Cochrane Database of Systematic Reviews 2009, Issue 2
- Galton F (1872) Statistical Inquiries into the Efficacy of Prayer, Fortnightly Review, No. LXVIII.
- Brown C et al. (2010) Study of the Therapeutic Effects of Proximal Intercessory Prayer (STEPP) on Auditory and Visual Impairments in Rural Mozambique Southern Medical Journal, Vol. 103, Issue 9.
Study 9: Benson (Harvard, Templeton Foundation); Prayer for Cardiac Patients
The John Templeton Foundation financed this study, intending it to be the definitive answer on the efficacy of prayer. They spent $2.4 million and enlisted 1.7 million people to pray. The study looked at 1802 heart patients from several prestigious medical centers. Like other studies this one had double-blinded prayed-for and non-prayed-for groups. But they also added a third group, which was explicitly told they would receive prayer. Intercessors were instructed to pray "for a successful surgery with a quick, healthy recovery and no complications." By all accounts the study was properly controlled and blinded (except for the third group, who knew they would be prayed for). The conclusion of the study was:
Intercessory prayer itself had no effect on complication-free recovery from CABG [coronary artery bypass graft surgery], but certainty of receiving intercessory prayer was associated with a higher incidence of complications.
In other words, there was no significant difference between the blinded prayed-for and not-prayed for groups. Overall, most commenters say the study was done well, but there was criticism of the fact that no pictures of the patients were given to the prayer-givers, and only first names and last initials were used. Also, prayer-givers were instructed to include the phrase "for a successful surgery with a quick, healthy recovery and no complications" in the prayers, and some reported that this was unnatural for them.
One curious outcome of this study is that the group that knew they were going to be prayed for did worse, at a statistically significant level. The experimenters speculate the patients may have felt "hey, if some stranger needs to pray for me, I must be really sick", and responded poorly because of that. This is a possible explanation, but the result is still surprising: normally placebos are quite powerful medicine, and if patients were told they were receiving a treatment that they believed would be beneficial, we would expect improved results.
Perhaps a more balanced experimental design would include a fourth group: one that knows they are not being prayed for. Such a study was done by Walach et al. on chronic fatigue syndrome patients. They found that there was no significant difference between the blinded treatment and non-treatment roups, but that the patients who knew they were being prayed for did better than the ones who knew they were not. This suggests that, even if prayer itself has no effect, the expectation of prayer has an important placebo effect, and should be considered as part of a treatment program.
Study 10: Aviles (Mayo Clinic); Prayer for Cardiac Patients
This study of 799 subjects was similar to the Benson study above. There was no third group, but they did separate both the prayed-for and non-prayed-for groups into low-risk and high-risk. The study appears to be well-controlled and blinded. The conclusion was:
As delivered in this study, intercessory prayer had no significant effect on medical outcomes after hospitalization in a coronary care unit.
Study 11: Sloan (Duke); Prayer for Cardiac Patients
This study of 748 heart patients differs from the other two in that it enlisted 12 different denominations to do the prayer: Jews, Muslims, Buddhists, and various Christian denominations. The study also considered soothing music, imagery and touch therapy, known as MIT. All together there were four groups: prayer or non-prayer crossed with MIT or non-MIT. The conclusion:
Neither therapy alone or combined showed any measurable treatment effect on the primary composite endpoint of major adverse cardiovascular events at the index hospital, readmission, and 6-month death or readmission.
Study 12: Masters (Syracuse); Meta-Analysis of Prayer
This meta-analysis looked at 14 prayer studies. They looked for all the studies published before August 2005 matching the terms "intercessory prayer" in the PsycInfo and Medline databases, and also looked at references from these articles and from review articles. The conclusion was:There is no scientifically discernible effect of IP [intercessory prayer] as assessed in controlled studies.
Study 13: Hodge (Arizona); Meta-Analysis of Prayer
This meta-analysis looked at 17 studies, including many of the same studies as Masters. Hodge found that there was a difference in favor of prayer that is statistically detectable, but that the difference in outcomes is not clinically important:Overall, the meta-analysis indicates that prayer is effective. Is it effective enough to meet the standards of the American Psychological Association's Division 12 for empirically validated interventions? No. Thus, we should not be treating clients suffering with depression, for example, only with prayer.One serious problem with this meta-analysis is that it includes the discredited Cha/Wirth study. Masters reported that removing Cha/Wirth eliminates 88% of the (non-significant) effect in his study; Hodge does not report whether the effect would persist if Cha/Wirth was removed.
Study 14: Roberts (Oxford); Meta-Analysis of Prayer
This new study (April 2009) searched ten databases for all randomized controlled trials relating to intercessory prayer. They found ten, and did a meta-analysis. This was part of the Cochrane Collaboration, which does systematic reviews of medical literature, and has very good guidelines for doing the analysis. The lead author of this study is Chaplain at Hertford College, Oxford. She and her colleagues report that there was no significant effect of prayer on death, clinical state, or re-hospitalization rates. They conclude that prayer is not promising enough to spend any more money studying, but since it appears to do no harm, there is no reason to recommend for or against it:These findings are equivocal and, although some of the results of individual studies suggest a positive effect of intercessory prayer, the majority do not and the evidence does not support a recommendation either in favour or against the use of intercessory prayer. We are not convinced that further trials of this intervention should be undertaken and would prefer to see any resources available for such a trial used to investigate other questions in health care.
Study 15: Galton (Royal Geographical Society); Prayer for British Royal Family

There is not a single instance, to my knowledge, in which papers read before statistical societies have recognized the agency of prayer either on disease or on anything else. ... Had prayers for the sick any notable effect, it is incredible but that the doctors, who are always on the watch for such things, should have observed it."Then Galton proposes an experiment of his own. He notes that British subjects frequently say prayers for the health of the Queen and other royals. Are those prayers effective? He shows a chart of the average lifespans of various groups:
| Group | Number | Avg. Life |
|---|---|---|
|
Members of Royal houses |
97 |
64.0 |
|
Clergy |
945 |
69.5 |
|
Lawyers |
294 |
68.1 |
|
Medical Profession |
244 |
67.3 |
|
English aristocracy |
1,179 |
67.3 |
| Gentry |
1,632 |
70.2 |
| Trade and commerce |
513 |
68.7 |
|
Officers in the Royal Navy |
366 |
68.4 |
| English literature and science |
395 |
67.6 |
|
Officers of the Army |
659 |
67.1 |
|
Fine Arts |
239 |
66.0 |
According to this table, the royals have the lowest life expectancy, so it appears that all those prayers are not working. Galton's study has an important place in the history of scientific reasoning, but it has several serious flaws. Most importantly, there is a selection bias (Warning Sign D4): a Royal child counts as a royal from birth, and thus a childhood death will bring down the Royal's average. In contrast a child born to a non-royal who dies before taking up a profession does not bring down the average of any profession. So we can say that Galton's study does not provide a serious result (perhaps he himself didn't think it was very serious either), while still admiring it as one of the first examples of evidence-based medicine.
There have been other studies along similar lines to Galton's. For example, a study by W.F. Simpson in 1989 found that graduates of Principia College, a school for Christian Scientists, who advocate prayer rather than medical treatment, had significantly higher death rates than similar students from secular colleges. This study does not have the confounds of Galton's study; if anything you would expect that the Christian Scientist students would have lower rates of dangerous practices such as drinking and smoking and thus you would expect them to live longer. Another study by Asser and Swan looked at 172 children who died after their parents refused medical care, preferring to rely on prayer. Asser and Swan found that, if you assumed the typical cure rates of medical treatments for the stated causes of death, at least 135 of these children would have recovered. However, this conclusion is invalid because of selection bias: it considers only the children who did die, and we don't have recovery rates on the children who did not die.
Study 16: Brown (Indiana); Proximal Intercessory Prayer
Here "Proximal Intercessory Prayer" (PIP) means the laying-on of hands: the healer touches the patient while praying for a health improvement. Brown et al. (see also an accompanying editorial) describe the protocol:Western and Mozambican Iris and Global Awakening leaders and affiliates who administered PIP all used a similar protocol. They typically spent 1-15 minutes (sometimes an hour or more, circumstances permitting) administering PIP. They placed their hands on the recipient's head and some- times embraced the person in a hug, keeping their eyes open to observe results. In soft tones, they petitioned God to heal, invited the Holy Spirit's anointing, and commanded healing and the departure of any evil spirits in Jesus' name. Those who prayed then asked recipients whether they were healed. If recipients responded negatively or stated that the healing was partial, PIP was continued. If they answered in the affirmative, informal tests were conducted, such as asking recipients to repeat words or sounds (e.g. hand claps) intoned from behind or to count fingers from roughly 30 cm away. If recipients were unable or partially able to perform tasks, PIP was continued for as long as circumstances permitted.They conclude:
Rural Mozambican subjects exhibited improved audition and/or visual acuity subsequent to PIP. The magnitude of measured effects exceeds that reported in previous suggestion and hypnosis studies.This study is instructive because it achieves a rare pentafecta, triggering all five of the most important experiment design warning signs:
- D1: Lack of a Randomized Controlled Trial. There was no control group; all subjects were in the treatment group. That means the conclusion is exceptionally poor: they can't say that their patients who received treatment did better than patients who didn't. All they can do is compare their patients to ones in completely different studies. That comparison is worthless.
- D2: Lack of Double-Blinding. There was no blinding; patients and healers (who were also the test scorers) both knew that everyone was in the treatment group.
- D3: Too Few Subjects. There were only 24 subjects in the treatment group (and no control group).
- D4: The Wrong Subjects. Rather than choose a cross-section of subjects, the experimenters specifically chose subjects from rural Mozambique who were attending an evengelical revival meeting--subjects who would be favorably inclined to (consciously or unconsciously) demonstrate a benefit from prayer. (The experimenters note that previous trials in the USA had negative results.)
- D5: The Wrong Questions. Subjects self-assessed when they were healed, and were then tested with eye charts and an audiometer. The problem with this is that the tests are still subjective, and the experiment was not double-blinded. So, if a subject says the letter on an eye chart is "E, no F? E?", the healer may well reason "Well, he said he was improved, and I know that my PIP treatment is powerful, so I'll mark that one as correct." With no blinding, no control group, and no purely objective tests, we can't really say if the results show anything at all.
- Control group: there should have been a control group that did not receive PIP. If it were me, I would have had three groups, one that received touch and prayers, one that got just the touch (perhaps with a substitute voice message, as described below), and one that got neither (perhaps with some alternative placebo treatment). That would help distinguish whether the touch or voice or both are important.
- Blinding: Admittedly it is harder to blind a study that involves active touching than one that involves remote prayer. Still, it would have been easy to properly single-blind this study. For example, you could give the subjects headphones and eye shades so that they do not see or hear whether the healer is praying or not. Alternatively, if it is important for the patient to hear the "soft tones", the study could have used healers who spoke a different language from the patients, with one group reciting prayers and another reciting some other script. That takes care of single-blinding; for double-blinding the study should have had someone other than the healer administer the post-treatment hearing and vision tests, someone who did not know which group the patient was in.
- Number of subjects: A hundred subjects split across two groups would have been much better.
- Wrong subjects: Results from each population tested should have been reported. Subjects should have been objectively evaluated for hearing/vision before, immediately after, and several days after treatment. That, along with a proper control group, should suffice.
- Wrong questions: This problem goes away once we have proper double-blinding and a control group.
Conclusions
Conclusion 1: Assessing the Evidence for Intercessory Prayer
Before doing the research for this essay, I had had a vague idea from reading various newspaper reports that studies of the medical efficacy of prayer were mixed: some studies showed a positive effect, some not. In fact, after actually reading the 14 studies above, a different picture emerges. We can grade each study as positive (P), negative (N), or flawed (F):
| Num | Result | Author | Comment |
|---|---|---|---|
| 1 | (F) | Achterberg | Clearly shows that brains do not behave completely randomly while in an fMRI machine. However, poor experimental design means we can't tell if the variation is due to anxiety or boredom or to distance intentionality. |
| 2 | (P,N) | Byrd | A mostly well-done study that is negative on most variables; on all variables when you combine with Harris. |
| 3 | (P,N) | Harris | A well-done study that is negative on most variables; on all variables when you combine with Byrd. |
| 4 | (F) | Tloczynski | Too few subjects to draw any conclusion. |
| 5 | (F) | Cha | The work of a felony fraudster and a plagiarist and can't be taken seriously. |
| 6 | (F) | Leibovici | Intended to be taken as a joke and is best interpreted that way. |
| 7 | (F) | Benor | Reporting on unpublished studies that are difficult to evaluate, using the flawed methodology of vote-counting. |
| 8 | (F) | Klingbeil | Never published any peer-reviewed studies. |
| 9 | (N) | Benson | A well-done study with all negative results. |
| 10 | (N) | Aviles | A well-done study with all negative results. |
| 11 | (N) | Sloan | A well-done study with all negative results. Together these are the three best. |
| 12 | (N) | Masters | A meta-analysis with negative results. |
| 13 | (F) | Hodge | A meta-analysis with some positive results, but the author claims the results are not clinically important. Also, it seems likely that the positive results stem solely from the discredited Cha study. |
| 14 | (N) | Roberts | A meta-analysis with negative results. |
| 15 | (F) | Galton | Best treated as a joke. |
| 15 | (F) | Brown | Got every experiment design choice wrong. |
In sum we find 9 flawed studies (from which we can draw no conclusion) and 5 clear negative studies (which say that for the conditions they studied, there is no solid evidence that intercessory prayer performs better than no prayer). There are also two good studies, Byrd and Harris, which individually show a positive effect of prayer on some variables and no effect on other variables, but taken together are negative: they show that no variable has a consistent, repeatable effect. It certainly looks like intercessory prayer, when measured in a scientific experiment, is not effective. Why is the impression from actually reading the studies so different from my original impression from reading newspaper reports? It may be because, as I write elsewhere, some reporters are more interested in giving "both sides of the story" than in doing a little work to discover if there is actually compelling evidence to support a point of view. Also, it is easy for a reporter to jump from "the study was significant at the 5% level" to "it works!", and finally, reporters never mention the studies that are not published.
Conclusion 2: Religious Implications
Happily, there's something in the results of these studies to please everyone, regardless of their religious beliefs:- Old Testament Theists can point to Deuteronomy 6:16, which states "You shall not put the Lord your God to the test" and claim that of course prayer doesn't work when part of an experiment, but it does work otherwise.
- Theists of any faith can say that God works in mysterious ways, has a plan for each person's eternal soul, and does not care to change that plan just because someone asks. Or, since none of the studies actively prohibited an outsider from praying for a subject, it may be that subjects in both the control and treatment groups were in fact prayed for, and God does not work by majority rule.
- Theists of particular doctrines can say that the prayers were performed incorrectly, according to their doctrine.
- Deists can say the results are consistent with a God who created the Universe and passively oversees it, but does not answer prayers.
- Atheists can use the results as evidence against a God.
Conclusion 3: Assessing Dossey
 Larry Dossey M.D. seems like a a sensible, intelligent, nice guy, dedicated to helping people.
How could he look at the same studies we have covered here
and see an overwhelming
preponderance of evidence for the efficacy of prayer, rather than the
reverse?
How could he say he found "no flaws" in Achterberg, when we could so easily
find seven serious flaws? (I recognize that Achterberg is a co-author with Dossey's
wife, so he has reasons to be charitable.)
How could Dossey support the Cha/Wirth/Lobo study in
January 2007, when he must have known by then that Lobo had repudiated
the study and
Wirth had been convicted of fraud? How could Dossey call the Leibovici study
"an amazing example" of the effectiveness of prayer, when Leibovici himself
saw it as a joke, and called it a "non-study"?
How could Dossey cite Tloczynski, a non-blinded study with 8 patients, and omit Benson,
a double-blinded study with 1.7 million that is generally regarded as the best study in the field? I realize
the
interview was a short piece, but citing the six studies Dossey does and
failing to mention Benson, Aviles and Sloan would be like an historian
arguing that Germany
is the greatest military power in the history of the world by citing the
Franco-Prussian War -- and neglecting to mention World War I or World War II.
How could Dossey do that?
Larry Dossey M.D. seems like a a sensible, intelligent, nice guy, dedicated to helping people.
How could he look at the same studies we have covered here
and see an overwhelming
preponderance of evidence for the efficacy of prayer, rather than the
reverse?
How could he say he found "no flaws" in Achterberg, when we could so easily
find seven serious flaws? (I recognize that Achterberg is a co-author with Dossey's
wife, so he has reasons to be charitable.)
How could Dossey support the Cha/Wirth/Lobo study in
January 2007, when he must have known by then that Lobo had repudiated
the study and
Wirth had been convicted of fraud? How could Dossey call the Leibovici study
"an amazing example" of the effectiveness of prayer, when Leibovici himself
saw it as a joke, and called it a "non-study"?
How could Dossey cite Tloczynski, a non-blinded study with 8 patients, and omit Benson,
a double-blinded study with 1.7 million that is generally regarded as the best study in the field? I realize
the
interview was a short piece, but citing the six studies Dossey does and
failing to mention Benson, Aviles and Sloan would be like an historian
arguing that Germany
is the greatest military power in the history of the world by citing the
Franco-Prussian War -- and neglecting to mention World War I or World War II.
How could Dossey do that?
After reading Tavris and Aronson's book Mistakes Were Made (but not by me), I understand how. Dossey has staked out a position in support of efficacious prayer and mind-over-matter, and has invested a lot of his time and energy in that position. He has gotten to the point where any challenge to his position would bring cognitive dissonance: if his position is wrong, then he is not a smart and wise person; he believes he is smart and wise; therefore his position must be correct and any evidence against it must be ignored. This pattern of self-justification (and self-deception), Tavris and Aronson point out, is common in politics and policy (as well as private life), and it looks like Dossey has a bad case. Ironically, Dossey is able to recognize this condition in other people -- he has a powerful essay that criticizes George W. Bush for saying "We do not torture" when confronted with overwhelming evidence that in fact Bush's policy is to torture. The essay, argues that Bush has slipped into self-deception to justify himself and ward off cognitive dissonance. Just like Dossey. Dossey may have a keen mind, but his mind has turned against itself, not allowing him to see what he doesn't want to see. This is a case of mind over mind, not mind over matter.
Conclusion 4: Final Lessons
- If you aren't trained to recognize the types of errors I outline here and in my other essay, you can easily interpret a claim that "pneumonia was significantly less in the treatment group at the p=5% level" as meaning "there is a 95% chance that treatment is effective in reducing cases of pneumonia." After reading these essays you should realize that the two statements are not at all equivalent (regardless of whether the treatment is prayer, antibiotics, or anything else).
- I really like that Dossey said "We need a single standard where we subject both conventional and alternative medicine to the same high standards." I agree with Dossey that the standard for publication in medical journals should be more strict. Perhaps Victor Stenger is right in saying that studies should be accepted only with p closer to 0.1% rather than 5%, but I don't think that relying solely on the p value is the right way to decide.
- In fact, I'm questioning the whole idea of p values, or at least the idea that they should be so prominent in publications. A recent article by J. Scott Armstrong says "I briefly summarize prior research showing that tests of statistical significance are improperly used even in leading scholarly journals. Attempts to educate researchers to avoid pitfalls have had little success. Even when done properly, however, statistical significance tests are of no value." By that he means that it is always better to give confidence intervals rather than significance levels. If I say that X is a better treatment than Y with significance p=5%, you haven't learned much about the magnitude of the difference between X and Y. But if I say the 95% confidence interval for X is a 55% to 67% cure rate and the corresponding interval for Y is 42% to 54%, then you have a much better idea of the real difference.
- I think it would be great if there were an online international registry of experiments: when you start an experiment, you register your hypothesis and methodology and get a timestamp. Your submission could be kept secret for a year or two if you desire. When you go to publish, you need to show that your experiment was properly registered ahead of time. If you fail to publish, researchers still have a record of file-drawer effect experiments.
- Anyone can learn to be a better judge of evidence. This essay and its companion attempt to teach the basics.
By the way, my relative pulled through the surgery with no complications. Hmm, were all you readers praying for a good outcome retroactively? Maybe there is something to this retroactive intercessory prayer thing after all...